- Home
- 32 b
- Frontiers Ps and Qs: Quantization-Aware Pruning for Efficient Low Latency Neural Network Inference
Frontiers Ps and Qs: Quantization-Aware Pruning for Efficient Low Latency Neural Network Inference
4.6 (532) · $ 10.50 · In stock

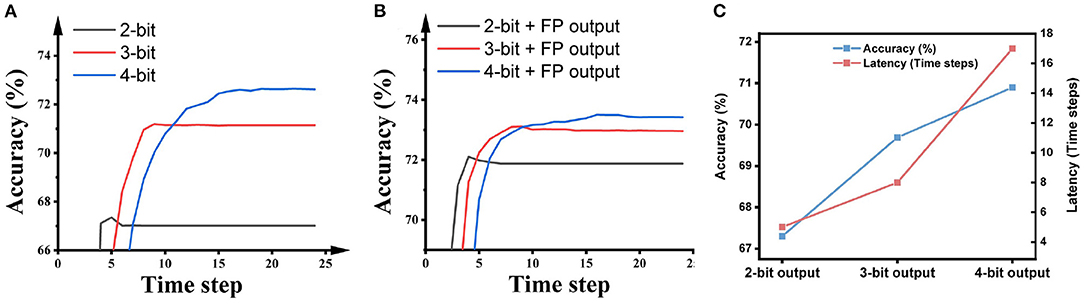
Frontiers Quantization Framework for Fast Spiking Neural Networks

PDF) End-to-end codesign of Hessian-aware quantized neural networks for FPGAs and ASICs

PDF) Neural Network Quantization for Efficient Inference: A Survey

Accuracy of ResNet-50 quantized to 2 and 4 bits, respectively.

arxiv-sanity
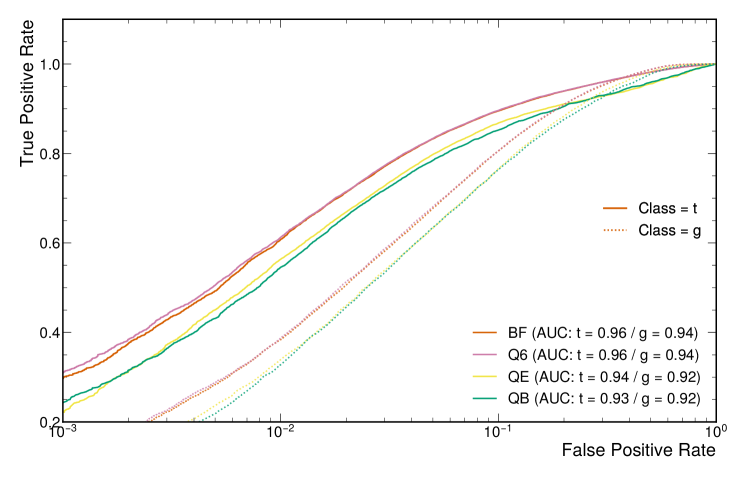
2006.10159] Automatic heterogeneous quantization of deep neural networks for low-latency inference on the edge for particle detectors

Quantization vs Pruning vs Distillation: Optimizing NNs for Inference
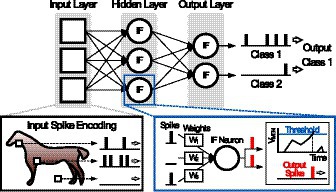
Frontiers Neuron pruning in temporal domain for energy efficient SNN processor design

PDF] Channel-wise Hessian Aware trace-Weighted Quantization of Neural Networks

Network Pruning










